K-Means的中心初始化惯用方式是随机初始化。也就是说:从training set中随机挑选出K个
作为中心,再进行下一步的K-Means算法。
这个方法很容易导致收敛到局部最优解,当簇个个数(K)较小(2<K<10)时,我们可以重复
多次K-Means,记录下他们的每个的cost function的值(如下图),其中cost function最小的便是
最优聚类结果了。
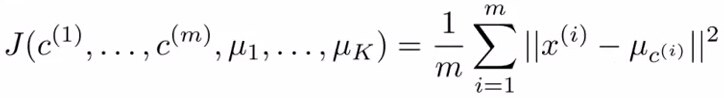
本文共 249 字,大约阅读时间需要 1 分钟。
K-Means的中心初始化惯用方式是随机初始化。也就是说:从training set中随机挑选出K个
作为中心,再进行下一步的K-Means算法。
这个方法很容易导致收敛到局部最优解,当簇个个数(K)较小(2<K<10)时,我们可以重复
多次K-Means,记录下他们的每个的cost function的值(如下图),其中cost function最小的便是
最优聚类结果了。
转载于:https://www.cnblogs.com/instant7/p/4149472.html